Découvrez Azure Data Services
Microsoft Azure Data Services
Un choix complet de services pour mettre en place votre plateforme de Data Intelligence
Choisir Microsoft Azure pour sa plateforme de Data Intelligence, c’est bénéficier pleinement des atouts du Cloud (puissance de calcul, stockage démultiplié, évolutions continues, etc…).
Mais c’est avant tout la possibilité de disposer de services applicatifs (Software as a Service) déjà développés. Leurs fonctionnalités permettent d’utiliser simplement les dernières innovations telles que l’IA.
Choisir un Cloud tel qu’Azure pour la data, c’est également oublier les exigences de matériel, de câblage ainsi que la majorité des installations d’applications nécessaires pour disposer d’une infrastructure IT fonctionnelle et sécurisée. Il n’est pas non plus nécessaire de déployer les actualisations (patchs) imposées par les éditeurs pour bénéficier des dernières versions et ne pas risquer de subir des failles de sécurité.
Concernant les data, cela permet de diminuer les opérations d’administration (jobs de maintenance comme les backups, patchs de sécurité de SQL Server). Il y a bien sûr toujours des décisions à prendre, mais pas de surveillance forte à mettre en place.
Choisir Azure pour mettre en place sa plateforme de Data Intelligence, c’est aussi bénéficier d’un paiement à l’utilisation et donc proportionnel au véritable usage de la solution.
Déployer sa plateforme de Data Intelligence dans Azure
L’objectif est de mettre en place une solution de Data Intelligence, de bénéficier d’une solution accessible par les acteurs actuels et futurs dans un contexte sécurisable. Pour cela, il faudra tout de même déployer la solution : Kwanzeo peut vous aider à accélérer cette étape en la réalisant pour vous ou en vous fournissant des scripts sous forme de QuickStarter.
Découvrez comment déployer Azure Data Services dans la série des vidéos Kezako.data
Épisode 1. Le Portail Azure
Épisode 2. Synapse Analytics — Partie Pool SQL
Que trouve-t-on dans l´offre Microsoft Azure liée à la Data Intelligence ?
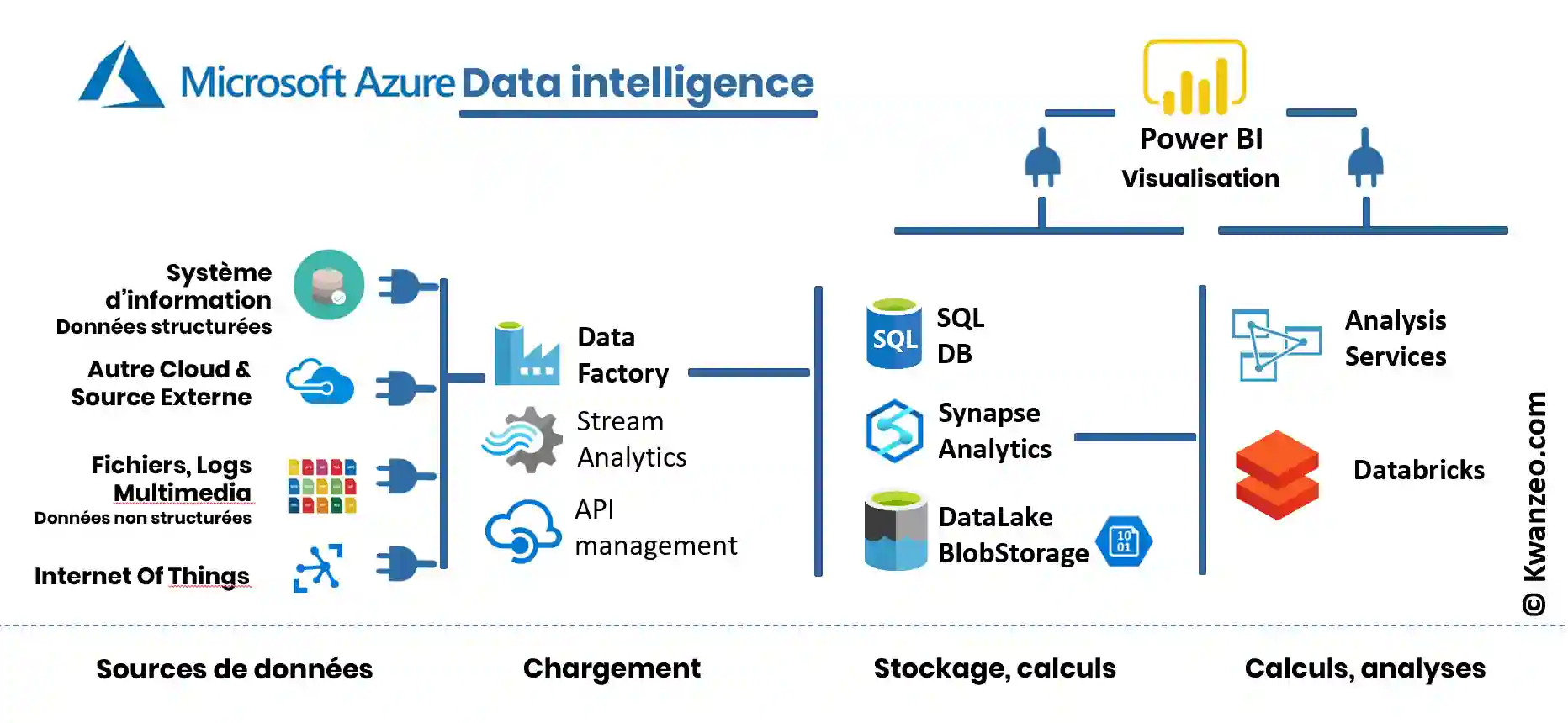
Flux de données : Azure Data Factory
ADF (Azure Data Factory) assure cette fonction dans l’offre Cloud de Microsoft. Les nouvelles capacités de traitement de la donnée dans les services cloud ont notamment permis l’émergence et la démocratisation de l’ELT (Extract, Load and Transform). La donnée est d’abord déplacée en l’état de la source vers la cible. Elle est, par la suite, traitée et unifiée.
Azure Data Factory (ADF) permet de se connecter à de nombreuses sources On-Prem et Cloud et de construire les flux des données graphiquement ou par code. L’objectif est de construire des pipelines et de profiter des 80 connecteurs natifs permettant de se connecter rapidement aux sources de données. La solution permet de mettre en place une démarche simple (CI/CD) de livraison continue et de surveillance des processus. D’autres moyens de se connecter pour extraire des données existent (Stream Analytics, connexions à des APIs…).
Stockage des données décisionnelles
Plusieurs moyens de stockage sont disponibles
Azure SQL Database
Azure Synapse Analytics
Azure Synapse Analytics (anciennement Azure SQL Data Warehouse) permet de créer plus efficacement le cœur du Data Warehouse et donne accès au Big Data.
Il permet le stockage de l’entrepôt de données (modélisation en étoile, operational Data Store (ODS) orienté décisionnel et Staging).
Il dispose de moyens d’interroger ces données y compris sur des gros volumes de données en optant pour la meilleure stratégie de calcul (serverless ou en dimensionnant le besoin).
Il est la solution pour répondre aux besoins de Business Intelligence et de Machine Learning. L’utilisateur peut opter pour un usage orienté interface ou écrire le code associé
via des langages classiques (usage de requêtes via T-SQL, langage Big Data avec Python, Scala, R et .NET). Azure Synapse se connecte à Azure Data Lake,
Azure Machine Learning, Azure Databricks et Power BI entre autres. Azure Synapse permet ainsi aux Data Engineers, aux
Data Scientistes et IT pros un véritable travail collaboratif. La scalabilité est très aisée. Si, par exemple, l’analyse d’un flux de données est gourmande
le matin mais ne l’est pas l’après-midi, la plate-forme sera réglée en conséquence. Le réglage des Data Warehouse Units (DWU) permet
de fixer la puissance de calcul et d’optimiser le ratio temps de calcul/coût. Cette élasticité est un atout majeur car elle permet de paralléliser les calculs.