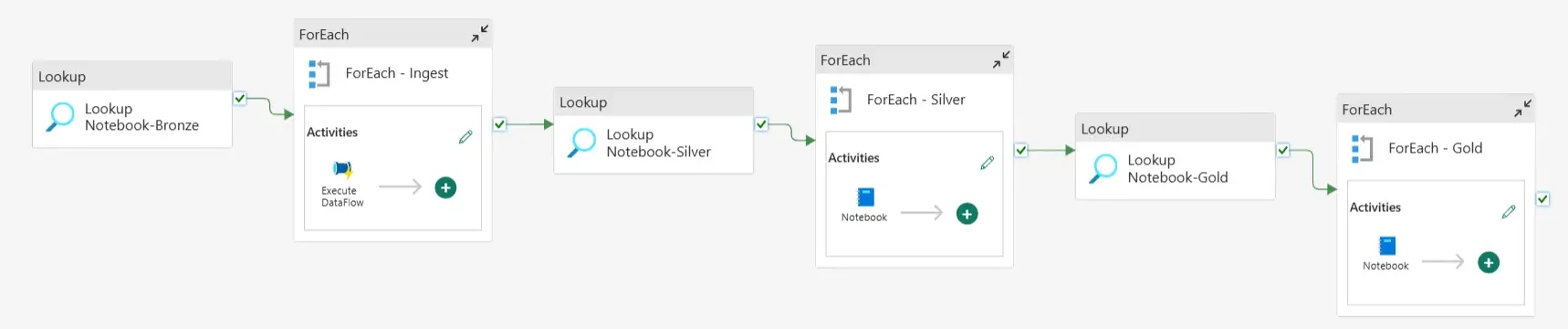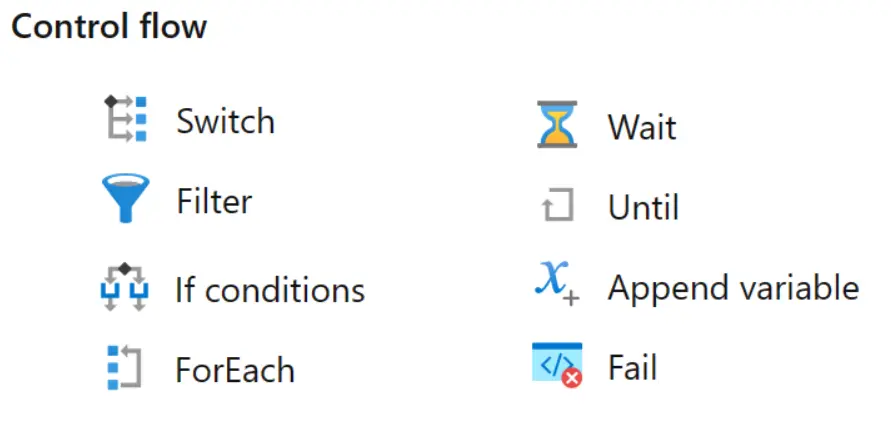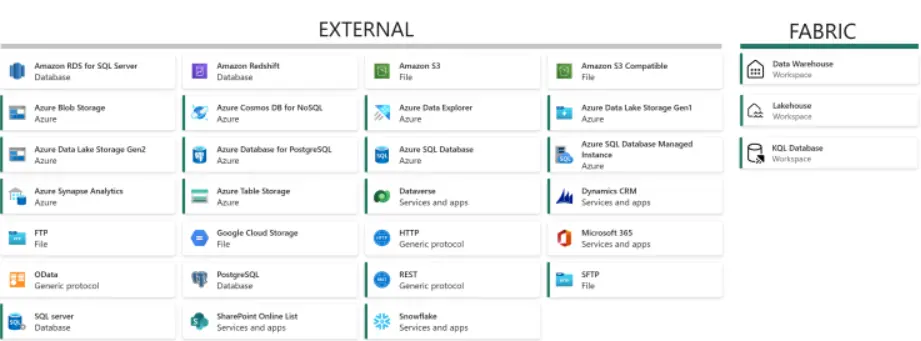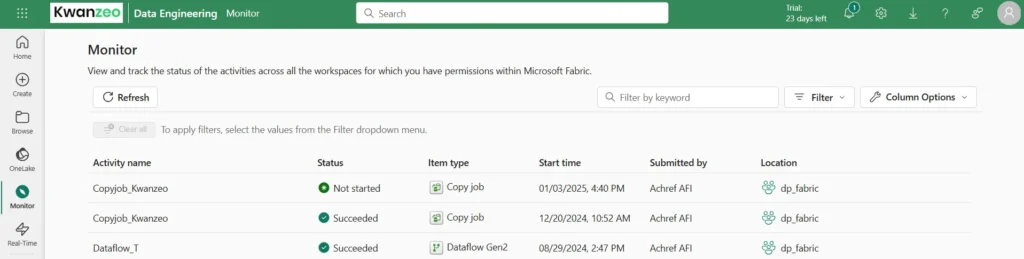
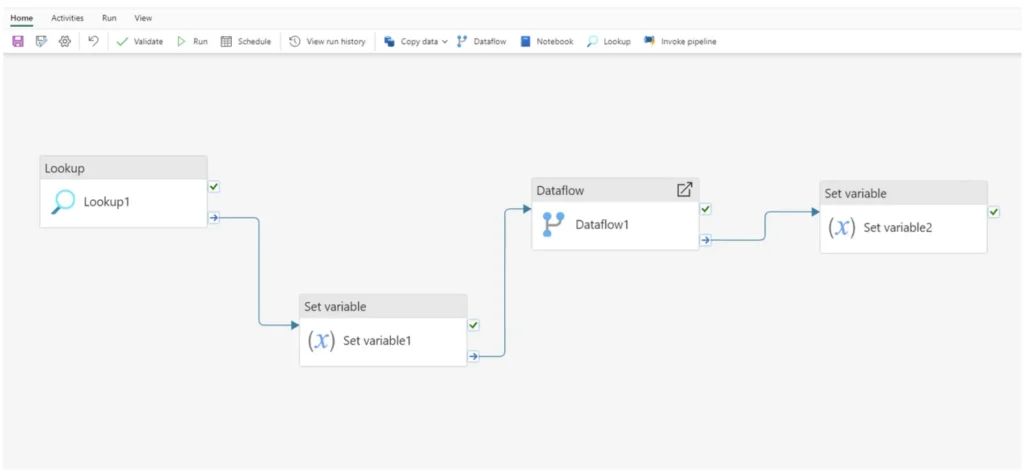
La pierre angulaire des pipelines de données sont les activités qui nous permettent de faire n’importe quoi, depuis la copie de données, la suppression de données, le contrôle du flux de travail lui-même, l’orchestration d’autres tâches de calcul, jusqu’à l’envoi de messages de communication avec Outlook et les équipes.
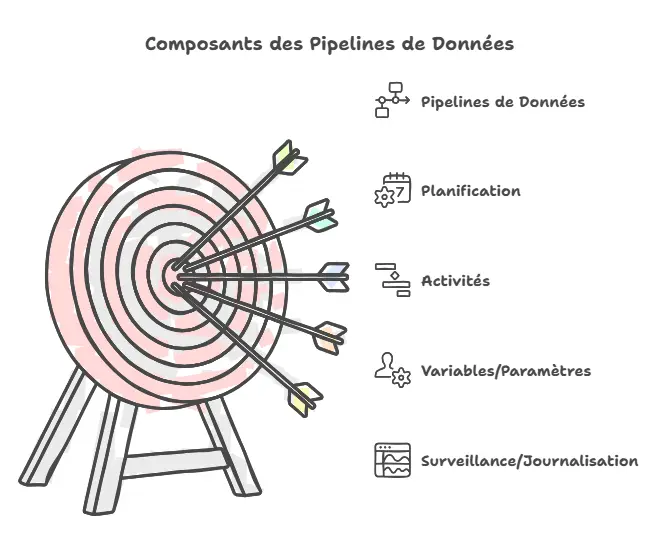
Les activités se composent de 4 types :
- Mouvement de données
- Transformer