Dataflow Gen2 dans Microsoft Fabric
Dataflow Gen2 est un outil ETL (Extract, Transform, Load) basé sur le cloud, conçu pour des processus de transformation de données évolutifs. Il vous permet d’extraire des données de diverses sources, de les transformer à l’aide d’un ensemble complet d’opérations et de les charger dans la destination souhaitée à l’aide de Power Query Online.
Dataflow Gen2 est un excellent outil pour créer des pipelines de données sans code via une interface visuelle, ce qui facilite la création rapide de pipelines de données.
Si vous êtes déjà familier avec Power Query ou que n’avez pas peur d’écrire du code, vous pouvez également utiliser le langage M («Mashup») sous-jacent pour créer des transformations plus complexes.
Dataflow Gen2 est un excellent outil pour créer des pipelines de données sans code via une interface visuelle, ce qui facilite la création rapide de pipelines de données.
Si vous êtes déjà familier avec Power Query ou que n’avez pas peur d’écrire du code, vous pouvez également utiliser le langage M («Mashup») sous-jacent pour créer des transformations plus complexes.
Pourquoi Choisir Dataflow Gen 2 ?
Dataflow Gen 2 peut nous aider à résoudre toute une série de défis grâce à la BI en libre-service :
Méthodes d’utilisation
Avantages
- Les flux de données facilitent l’accès en libre-service à des sous-ensembles d’informations d’entrepôt de données.
- Ils normalisent les données, fournissant des ensembles de données cohérents et de qualité.
- Les performances sont optimisées en permettant aux données d’être extraites une seule fois et réutilisées, ce qui est particulièrement avantageux pour les sources de données lentes.
- L’interface low-code simplifie l’intégration des données provenant de diverses sources.
- Connectivité étendue : prend en charge plus de 100 connecteurs.
Limites
- Les flux de données ne sont pas conçus pour remplacer un entrepôt de données.
- Ils ne prennent pas en charge la sécurité au niveau des lignes.
- Un espace de travail de capacité Fabric est requis pour les utiliser.
- Dataflow peut être utilisé dans la charge de travail Data Factory, l’espace de travail Power BI ou directement dans le Lakehouse. Cet outil est particulièrement utile pour les scénarios d’ingestion de données
Principales fonctionnalités des flux de données (Gen2)
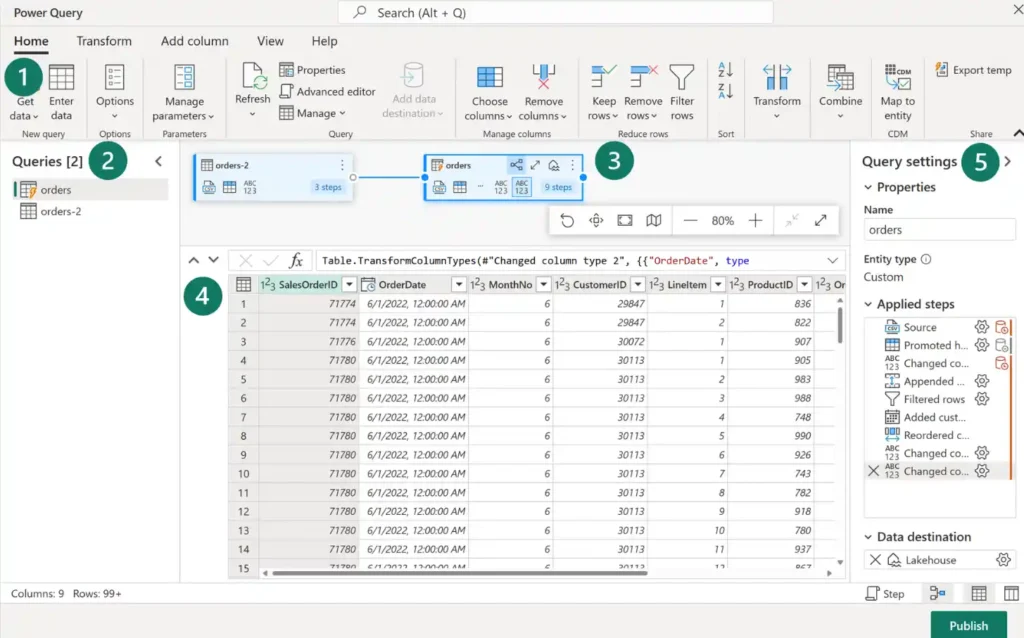
1/Power Query ribbon :
Connecteurs de source de données : prend en charge un large éventail de bases de données cloud et sur site jusqu’aux fichiers Excel, SharePoint, Salesforce, Spark et Fabric Lakehouses.
Transformations de données : inclut le filtrage, le tri, le pivotement, la fusion, le fractionnement, le remplacement de valeurs et la gestion des colonnes. Des fonctionnalités supplémentaires telles que le classement, les calculs de pourcentage et les sélections N haut/bas sont également disponibles.
2/Queries Pane : Ce volet affiche diverses sources de données, désormais appelées requêtes. Il permet de renommer, de dupliquer, de référencer et d’activer la mise en scène de ces requêtes.
3/Diagram View : Offre une représentation visuelle des connexions entre les sources de données et les transformations appliquées.
4/Data Preview Pane : Fournit un aperçu d’un sous-ensemble de données, aidant à déterminer les transformations nécessaires. Il permet des fonctionnalités interactives telles que le glissement des colonnes pour la réorganisation ou le clic droit pour le filtrage.
5/Query Settings Pane : Ici, chaque étape de transformation est répertoriée. La complexité de vos transformations s’observe à travers le nombre d’étapes appliquées. Ce volet permet également de définir le Lakehouse comme destination des données.
2/Queries Pane : Ce volet affiche diverses sources de données, désormais appelées requêtes. Il permet de renommer, de dupliquer, de référencer et d’activer la mise en scène de ces requêtes.
3/Diagram View : Offre une représentation visuelle des connexions entre les sources de données et les transformations appliquées.
4/Data Preview Pane : Fournit un aperçu d’un sous-ensemble de données, aidant à déterminer les transformations nécessaires. Il permet des fonctionnalités interactives telles que le glissement des colonnes pour la réorganisation ou le clic droit pour le filtrage.
5/Query Settings Pane : Ici, chaque étape de transformation est répertoriée. La complexité de vos transformations s’observe à travers le nombre d’étapes appliquées. Ce volet permet également de définir le Lakehouse comme destination des données.
Comment configurer Dataflows Gen 2 dans Fabric ?
Vous pouvez créer un Dataflow Gen2 dans Data Factory à l’intérieur de Fabric.
Soit via l’espace de travail et « Nouveau », soit depuis la page de démarrage de Data Factory dans Fabric.

Avec le flux de données Gen2, vous disposez du plus grand choix de systèmes sources à partir desquels lire les données :
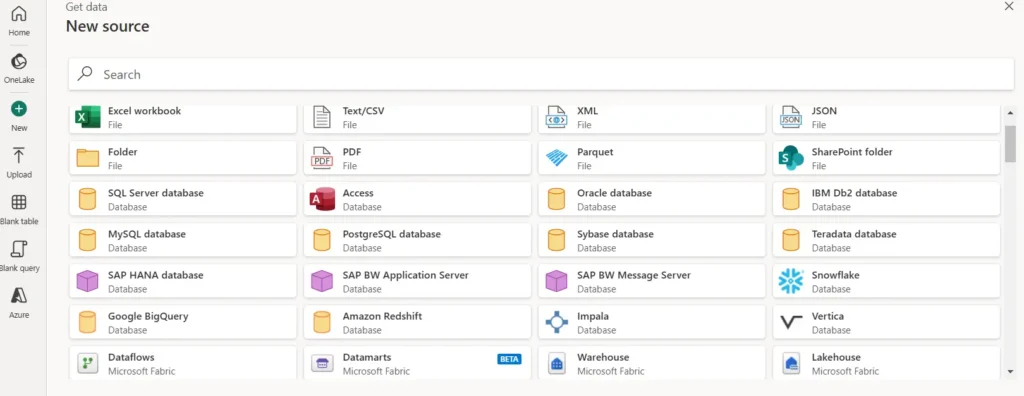
Ainsi que différentes destinations :
