Gouvernance des données et assistant IA
Qu'est-ce que Catalog de Coalesce (Ex CastorDoc)
Catalog de Coalesce est une solution conçue pour aider les entreprises à mieux organiser, comprendre et exploiter leurs données. Grâce à une documentation centralisée et automatisée, elle permet aux équipes de localiser rapidement les informations essentielles et de collaborer efficacement. Son intelligence artificielle intégrée facilite la recherche et l’analyse en langage naturel, offrant une meilleure accessibilité aux données. En parallèle, Catalog de Coalesce assure une gouvernance optimisée et une conformité aux réglementations en vigueur, garantissant ainsi un environnement structuré et sécurisé pour la gestion des actifs de données.
CastorDoc se positionne comme un outil résolument tourné vers les utilisateurs finaux.
Son objectif est double : à la fois rendre plus autonomes les utilisateurs finaux et également libérer du temps aux équipes data habituellement occupés à répondre aux questions des utilisateurs : comment est calculée cette donnée ? Est-elle fiable ? Où trouver telle autre information ?
Au final, ce positionnement doit faciliter l’utilisation du Data Catalog et par voie de conséquence, son adoption.
Fonctionnalité principale
Catalog de Coalesce offre tout un ensemble de fonctionnalités dont les principales sont les suivantes :
- Collecte de données : va permettre d’enrichir automatiquement le Data Catalog en métadonnées via des connecteurs comme des entrepôts ou bases de données (Oracle, PostgreSQL, SQL server, Snowflake…) , ou des outils de visualisation (Power BI, Qlik sense, Tableau…). Cette collecte est capable de récupérer également les descriptions existantes dans ces systèmes pour venir documenter, dans CastorDoc, les objets collectés.
- Lignage (Lineage) : le lignage consiste à pouvoir consulter de façon graphique l’utilisation d’un objet (un dashboard, un flux, une table ou un champ d’une table…) aussi bien en amont (provenance de l’objet) qu’en aval (utilisation de l’objet).
Utile pour les utilisateurs finaux mais également pour les utilisateurs IT qui peuvent ainsi voir simplement l’impact technique s’ils envisagent une modification sur un champ par exemple en visualisant les dashboards, tables, flux qui utilisent ce champ.
Le lignage va pouvoir être fait en automatique lors de la collecte via l’existence de code SQL ou code DAX PowerBI. - Glossaire (Knowledge): il s’agit des définitions métiers des données saisies dans CastorDoc. Il est également possible de lier ces définitions à des contenus présents dans Confluence ou Notion.
- Génération automatique d’étiquette (Tag) sur les données comme « New », source d’origine, information sensible et possibilité d’en créer de nouvelles
- Gestion d’indicateurs sur les données via la popularité (plus l’objet est utilisé, plus il est populaire) ou la qualité de la donnée.
CastorDoc permet également la gouvernance via l’attribution de rôle aux objets et la gestion des droits d’accès aux métadonnées du Data Catalog.
Un outil tourné vers les utlisateurs finaux
Catalog de Coalesce se positionne comme un outil résolument tourné vers les utilisateurs finaux.
Son objectif est double : à la fois rendre plus autonomes les utilisateurs finaux et également libérer du temps aux équipes data habituellement occupés à répondre aux questions des utilisateurs : comment est calculée cette donnée ? Est-elle fiable ? Où trouver telle autre information ?
Au final, ce positionnement doit faciliter l’utilisation du Data Catalog et par voie de conséquence, son adoption.
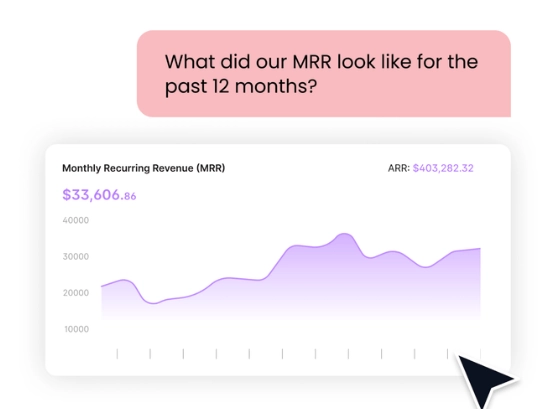
Outre les fonctionnalités habituelles qu’on retrouve dans un Data Catalog que l’on abordera par suite, CastorDoc s’appuie sur un assistant pour aider les utilisateurs à être plus autonomes lors de leur recherche et compréhension des données.
Cet assistant est un module IA (basé sur Copilot) disponible dans CastorDoc mais également intégré aux applications de tous les jours (navigateur Chrome, Teams ou Slack par exemple).


Contact
Faites-nous part de vos questions,
de vos enjeux et besoins/projets :
- En envoyant un mail via [email protected]
- En remplissant ce formulaire