DBT : L'outil clé pour la transformation des données
Dans le paysage actuel de la gestion des données, la capacité à transformer efficacement des données brutes en informations exploitables est cruciale pour les entreprises.
Data Build Tool (dbt) se distingue en permettant aux analystes et ingénieurs de données de réaliser des transformations directement au sein des data warehouses modernes, en utilisant des requêtes SQL.
En adoptant des pratiques d’ingénierie logicielle telles que le contrôle de version, les tests automatisés et la documentation intégrée, dbt offre une approche structurée et collaborative pour la transformation des données.
Cet article explore les fonctionnalités clés de dbt, ses avantages par rapport aux autres outils d’intégration de données et les contextes dans lesquels son utilisation est particulièrement bénéfique.
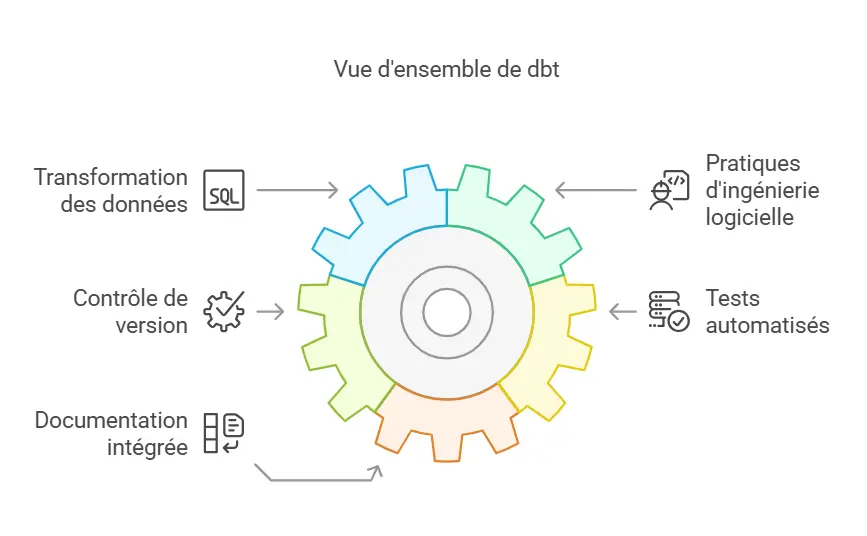
Qu'est-ce que dbt ?
Dbt est un outil open-source conçu pour faciliter la transformation des données au sein des data warehouses modernes. Il permet aux analystes et ingénieurs de données de transformer les données en utilisant des requêtes SQL, tout en adoptant des pratiques d’ingénierie logicielle telles que le contrôle de version, les tests automatisés et la documentation intégrée.
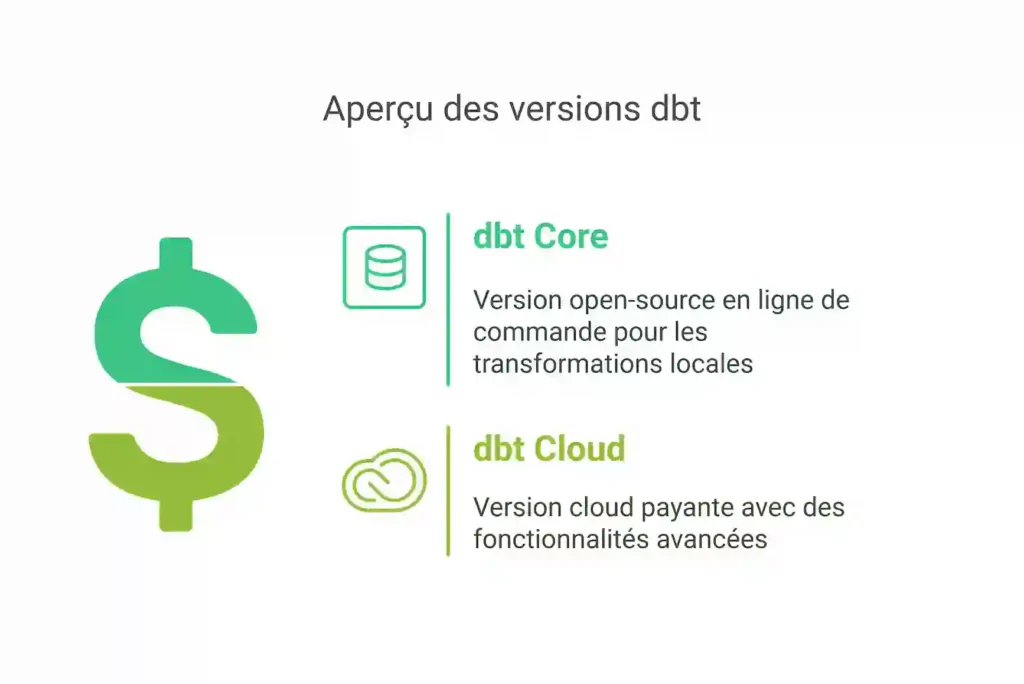
Versions de dbt :
dbt se compose de deux principales versions :
L’architecture de dbt Cloud comprend des composants statiques, toujours actifs pour assurer la haute disponibilité des fonctions essentielles, et des composants dynamiques, créés à la demande pour gérer des tâches.
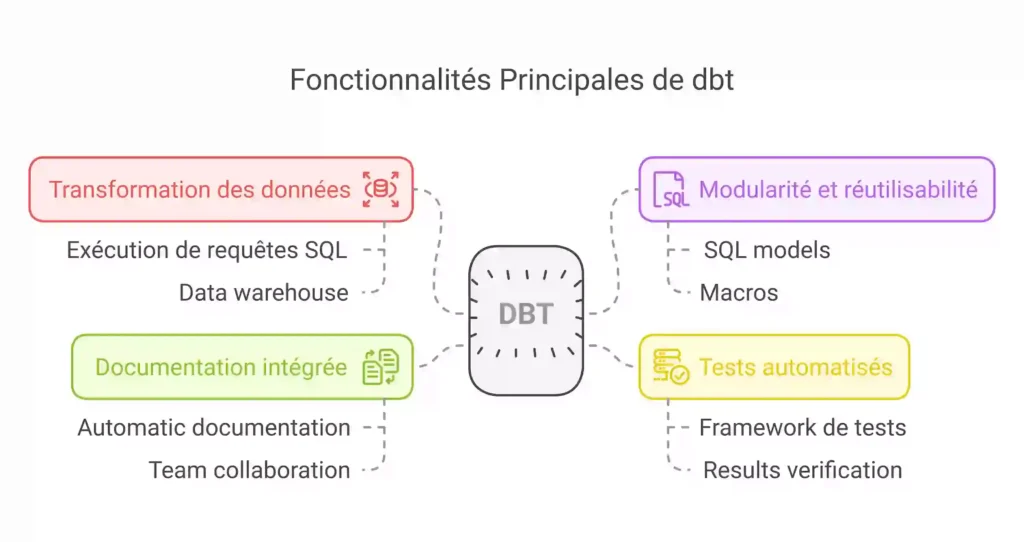
Fonctionnalités principales de dbt :
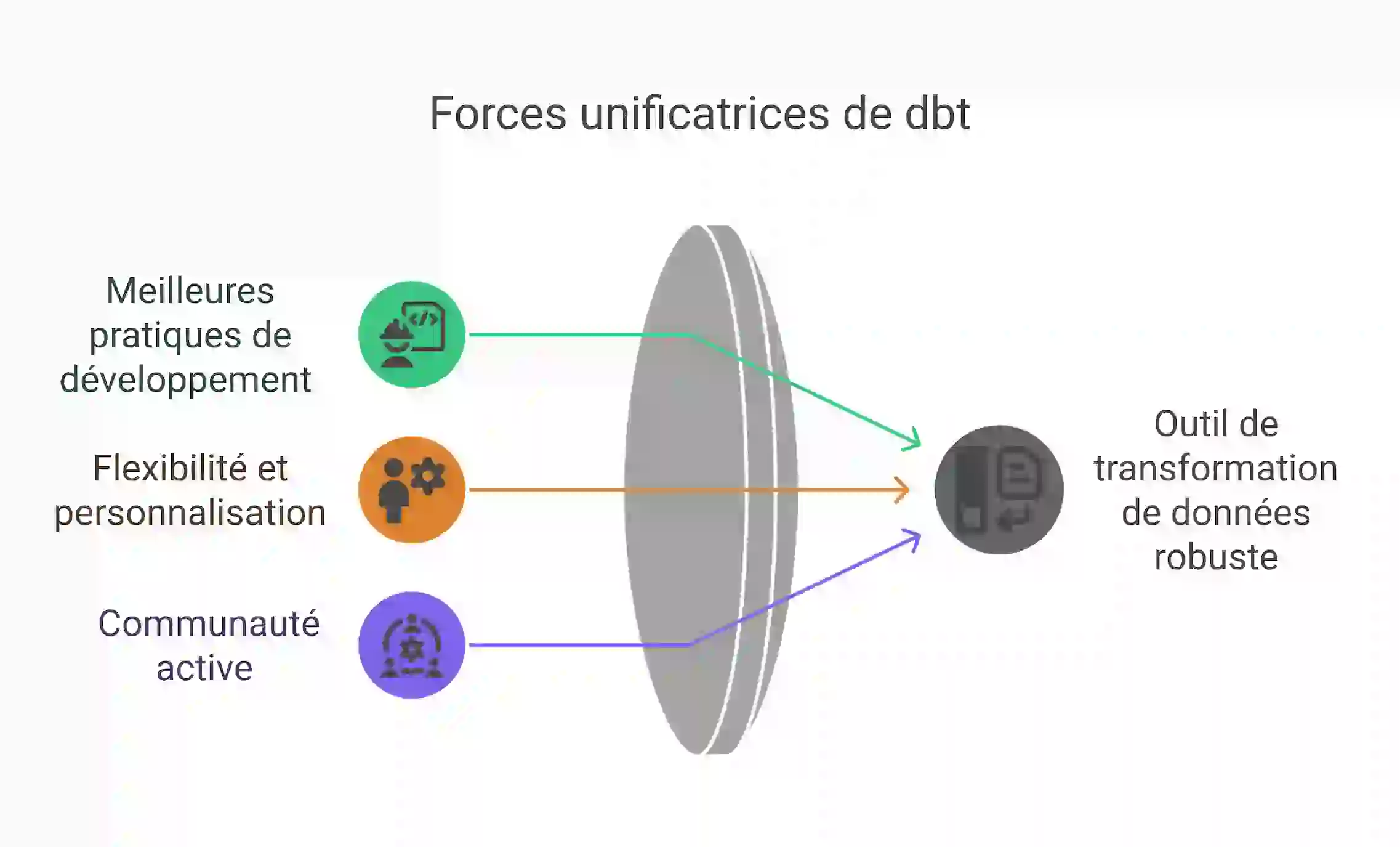
Ce qui distingue dbt des autres outils :
Contextes d'utilisation et avantages de dbt :

Structure d'un projet dbt :
La configuration globale du projet est centralisée dans le fichier dbt_project.yml, qui spécifie des informations essentielles telles que la version du projet, la configuration des modèles et les dépendances.

Fonctionnalités avancées de dbt :
- Vue (view) : Crée une vue dans la base de données, exécutée à la demande sans stockage physique des données.
- Table (table) : Stocke les données transformées physiquement, améliorant les performances des requêtes en évitant des calculs répétés.
- Éphémère (ephemeral) : Crée des tables temporaires non stockées dans le data warehouse, utilisées comme intermédiaires dans des transformations.